

강좌 & 팁
오늘은 인터럽트 동작에 대해 설명 하겠습니다.
인터럽트/익셉션 시퀀스
익셉션이 발생하면 다음과 같은 일들이 일어 납니다.
● 스태킹(8개의 레지스터들의 내용을 스택에 저장함)
● 벡터 페치(벡터 테이블에서 익셉션 핸들러의 시작 주소를 읽어들임)
● 스택 포인터, 링크 레지스터, 프로그램 카운터 업데이트
스태킹
익셉션이 발생하면, PC, PSR, R0-R3, R12, LR과 같은 레지스터들이 스택에 저장됩니다.
실행되고 있는 코드가 PSP를 사용하고 있다면 프로세스 스택이 사용될 것이며, 실행되고 있는 코드가 MSP를 사용하고
있다면 메인 스택이 사용될 것입니다.
메인 스택은 항상 핸들러에서 사용되기 때문에, 모든 중첩된 인터럽트들은 메인 스택을 사용 할 것입니다.
AHB인터페이스의 파이프라인의 속성 때문에, 주서와 데이터는 파이프라인 상태에 의해 오프셋이 됩니다.
명령어 페치가 시작되고 IPSR이 업데이트될 수 있도록, PC와 PSR의 값이 제일 먼저 스택에 쌓입니다.. 스태킹 후
SP는 N-32로 업데이트되며, 스택 메모리 안에 쌓여 있는 데이터의 정렬은 밑의 그림과 같다.
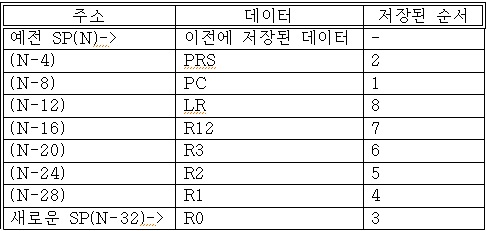
레지스터 R0-R3, R12, LR, PC, 그리고 PSR이 스택에 저장되는 이유는 C 표준에 따라 레지스터들을 저장하는 호출자가 있기
때문입니다. 이 정렬은 인터럽트 핸들러가 보통의 C 함수가 될 수 있게 해줍니다. 왜냐하면 익셉션 핸들러에 의해 변경될 수 있는 레지스터들의 스택에 저장되기 때문입니다.
범용 레지스터들은 SP 관련된 어드레싱을 사용하여 쉽게 접근할 수 있도록 하기 위해 스택 프레임의 끝에 위치합니다.
결과적으로 스택에 저장된 레지스터들을 사용하면 소프트웨어 인터럽트로 매개변수들을 전달하기가 쉽습니다.
벡터 페치
레지스터들을 스택에 저장하기 위해 데이터 버스가 사용되고 있을 때, 명령어 버스는 인터럽트 시퀀스의 다른 중요한 작업들을
수행합니다. 그것은 벡터 테이블에서 익셉션 벡터를 패치 합니다.
스태킹과 벡터 페치는 분리된 버스 인터페이스에서 수행되기 때문에, 동시에 수행될 수 있습니다.
레지스터 업데이트
스태킹과 벡터 페치가 완료되면, 익셉션 벡터는 실행을 시작할 것입니다. 익셉션 핸들러의 진입 단계에서는 많은 레지스터들이
업데이트됩니다.
● SP : 스태킹하는 동안 스택 포인터는 새로운 위치로 업데이트될 것입니다. 인터럽트 서비스 루틴을 실행하는 동안, 스택이
액세스되는 경우에는 MSP가 사용될 것입니다.
● PSR : IPSR이 새로운 익셉션 번호로 업데이트될 것입니다.
● PC : PC는 벡터 페치가 완료되고 벡터 테이블에서 명령어들을 페치하기 시작할 때 벡터 핸들러로 변결될 것입니다.
● LR : LR은 EXC_RETURN이라고 불리는 특정한 값으로 업데이트될 것입니다. 이 특정값은 인터럽트 리턴 동작을 야기합니다.
다은 많은 NVIC 레지스터들 또한 업데이틀될 것입니다.
익셉션 종료
익셉션 핸들러의 끝 부분에서는 인터럽트된 프로그램이 정상적으로 다시 실행될 수 있도록 하기 위해 시스템 상태를 복원하기
위한 익셉션의 종료 작업이 요구 됩니다.
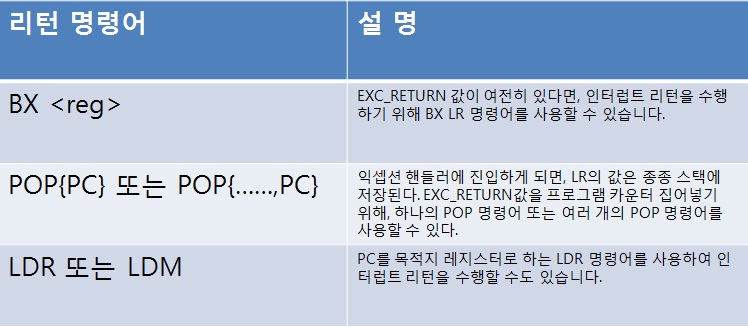
인터럽트 리턴 시권스를 발생시키기 위해서는 세 가지 방법이 사용될 수 있는데, 그것들은 모두 핸들러 시작에서 LR에 저장했던 특정한 값을 사용 합니다.
어떤 마이크로세서 아키텍처는 인터럽트 리턴을 위해 특별한 명령어를 사용합니다. 모든 인터럽트 핸들러가 C 서브루틴으로
구현될 수 있도록 하기 위해 Cortex-M3에서는 보통 리턴명령어가 사용됩니다.
인터럽트 리턴 명령어가 실행되면, 밑과 같은 과정이 수행 됩니다.
- 언스태킹 : 스택에 저장된 레지스털들이 복원될 것입니다. POP의 순서는 스태킹할 때와 동일합니다. 스택 포인터 또한 원래대로 변경될 것입니다.
- NVIC 레지스터 업데이트 : 익셉션의 활성 비트는 0으로 클리어될 것입니다. 외부 인터럽트의 입력이 다시 들어오면, 이 인터럽트 핸들러로 다시 진입하기 위해 펜딩 비트가 다시 1로 설정될 것입니다.
중첩 인터럽트
Cortex-M3 프로세서 코어와 NVIC에는 중첩 인터럽트가 지원됩니다. 중첩 인터럽트를 활성화하기 위해 어셈블러 래퍼 코드를 사용할 필요도 없습니다. 사실, 인터럽트 소스들을 위해 적절한 우선순위 레벨을 설정할 필요도 없습니다. 첫 번째로, Cortex-M3 프로세서 안에 있는 NVIC는 설정해 놓은 우선순위에 따라 분류됩니다. 그러므로 프로세서가 익셉션을 처리할 때, 동일하거나 더
낮은 우선순위를 가진 다른 모든 익셉션들을 블록화 될 것입니다. 두번째로, 자동화된 하드웨어 스태킹 및 언스태킹은 중첩된 인터럽트 핸들러가 레지스터 안에 있는 데이터를 잃지 않고도 실행될 수 있게 해줍니다.
하지만, 주의해야 할 점이 하나 있습니다. 많은 중첩 인터럽트가 가능하도록 메인 스택이 충분한지를 확인해 봐야 합니다. 각 익셉션 레벨은 8워드의 스택 공간을 사용할 것이며 익셉션 핸들러 코드는 추가적인 스택 공간을 필요로 할 것이기 때문에, 그것은 예상한 것보다 더 많은 스택 메모리를 사용할 수도 있습니다.
Cortex-M3에서는 재진입 익셉션을 허용되지 않습니다. 각 익셉션은 할당된 우선순위 레벨을 가지고 있고, 익셉션이 처리되고 있는 도중에는 동일하거나 더 낮은 우선순위를 가진 익셉션은 블록화되기 때문에, 핸들러가 끝날 때까지 동일한 익셉션은 수행될
수 없습니다. 이러한 이유로 SVC 명령어는 SVC 핸들러 안에서 수행될 수 없습니다. 그렇게 하면, 결함 익셉션이 발생할 것이기 때문입니다.
테일- 체인지 인터럽트
Cortex-M3는 인터럽트 지연을 개선하기 위해 많은 방법들을 사용하고 있습니다. 첫 번째로 살펴볼 방법이 바로 테일-체인입니다.
익셉션 발생하였을 때 프로세서가 그와 동일하거나 더 높은 우선순위의 다른 익셉션을 처리하고 있다면, 익셉션은 펜딩될 것입니다. 현재 익셉션 핸들러를 실행하는 것을 끝마쳤을 때, POP 대신 레지스터들이 스택으로 되돌아가서 그것을 다시 스택 안에 저장합니다. 언스태킹과 스태킹 과정은 생략됩니다. 이러한 방법은 두 익셉션 핸들러 간에 시간 차이를 상당히 줄여줍니다.
늦은 도착
인터럽트 성능을 개선하기 위한 또 다른 특징은 늦은 도착 익셉션 핸들링입니다.
익셉션이 발생하고 프로세서가 스태킹 과정을 시작할 때, 이 지연시간 동안 더 높은 우선순위를 가진 새로운 익셉션이 도착하면, 늦게 도착한 익셉션이 먼저 처리될 것입니다.
