

강좌 & 팁
삼성의 1bit용 NAND Flash ECC 알고리즘을 해부해 볼 호서대학교에 재학 중인
MS-OSEK Team의 지정웅 입니다.
저번 시간에 이어 오늘은 4byte를 건너뛰고 8byte 에서 1bit 에러 찾는 것을 한다고 했습니다.
자, 바로 시작!
하면 서운하니 드라마 처럼 이전 내용을 간단히 설명하도록 하겠습니다.
1. 전편 줄거리.
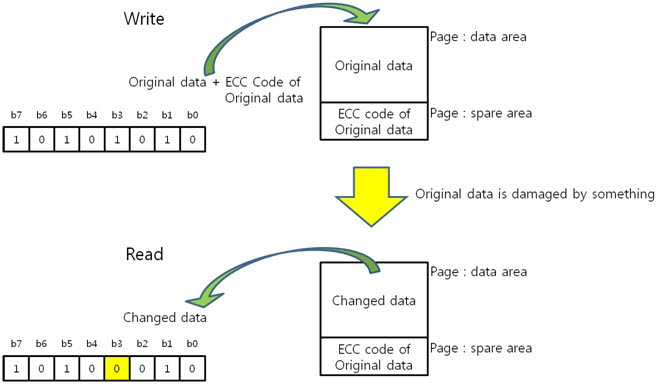
NAND는 가격대비 성능이 좋지만 데이터 연산 중 파워가 나가거나 여러 상황에 의해 데이터가 깨질 수 있습니다. 그렇기에 원본 데이터에 대한 ECC 코드를 만들어 spare영역에 저장하고 변환된 데이터의 ECC 코드를 만들어 비교를 하여 에러를 찾아 NAND의 안정성을 높입니다.
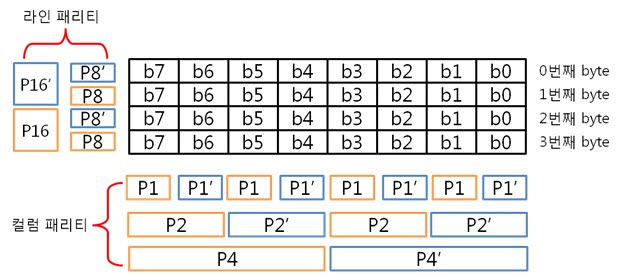
아래는 4byte 일때 라인 패리티 쌍과 컬럼 패리티 쌍을 나타낸 것입니다.
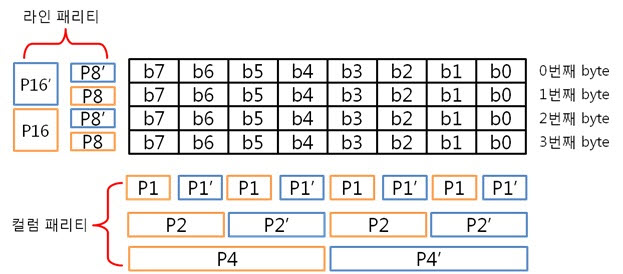
ECC 코드는 ‘컬럼 패리티’와 ‘라인 패리티’로 이루어져 있습니다. 컬럼 패리티는 X의 위치를, 라인 패리티는 Y의 위치를 찾는데 쓰입니다.
하지만 원본 데이터나 변환된 데이터 ECC 코드로는 X, Y의 위치를 찾지 못합니다. 아래와같이 최종 ECC 코드를 만들어 X, Y의 위치를 찾습니다.
원본 데이터의 ECC 코드 (+) 변환된 데이터의 ECC 코드 = 최종 ECC 코드
이렇게 나온 최종 ECC 코드를 표현식으로 바꾸어 에러가 난 비트의 X, Y의 위치를 찾습니다. 표현식을 만드는 규칙은 아래와 같습니다.
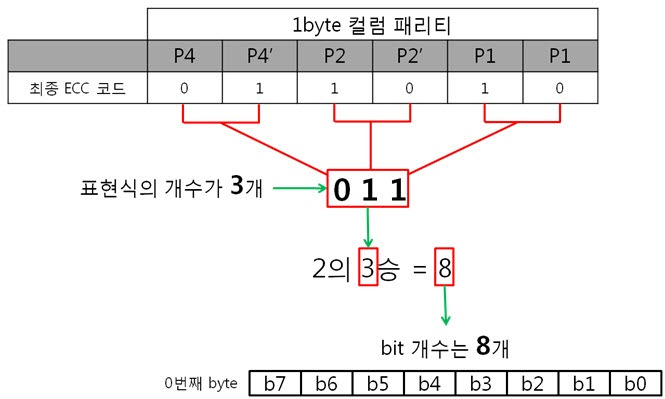
ex) 패리티의 쌍을 이용해 표현식으로 바꾼다. (P4와 P4’쌍, P2와 P2’쌍, P1과 P1’쌍)
예를 들어 P4 = 0, P4’ = 0 일 경우, 표현은 0
P4 = 1, P4’ = 0 일 경우, 표현은 1
P4 = 0, P4’ = 1 일 경우, 표현은 0
P4 = 1, P4’ = 1 일 경우, 표현은 1
아래 예를 보면 번뜩! 하고 떠오르실 겁니다.
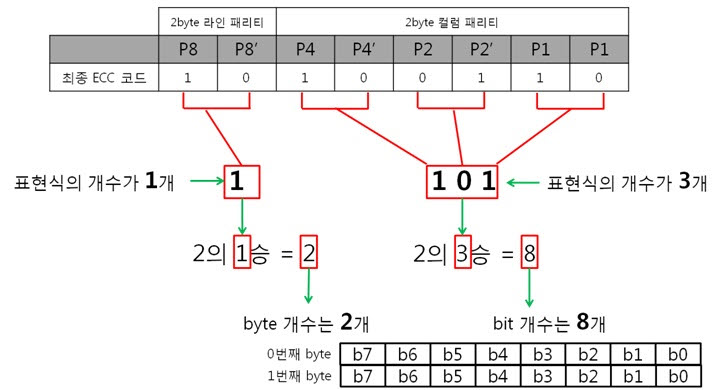
ex) 2byte의 최종 ECC 코드를 표현식으로
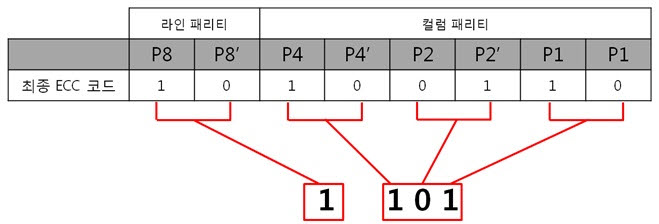
라인 패리티는 ‘1’을, 컬럼 패리티는 ‘101’ 이라는 결과를 10진수로 바꾸어 보면 라인 패리티는 1, 컬럼 패리티는 5 라는 숫자가 나옵니다. 에러가 난 위치는 1번째 byte(행)의 5번째 bit(열) 입니다. 라인 패리티는 Y의 위치를, 컬럼 패리티는 X의 위치를 찾는 것 이라 생각하면 됩니다.
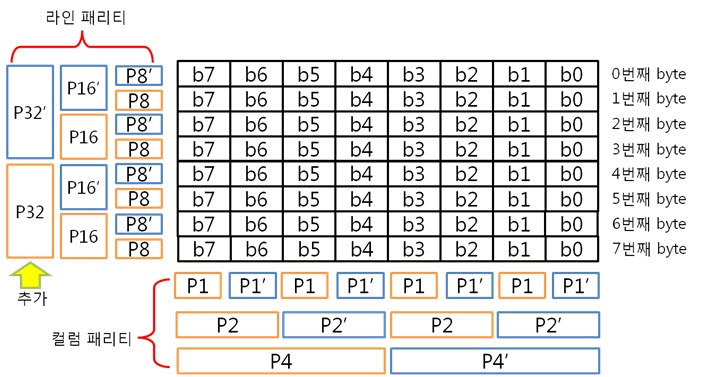
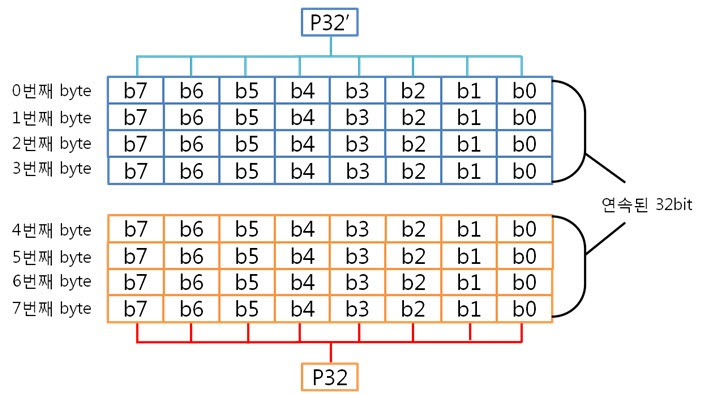
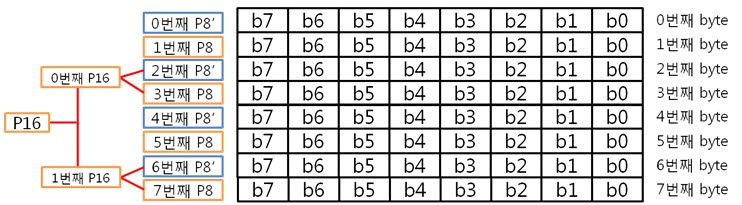
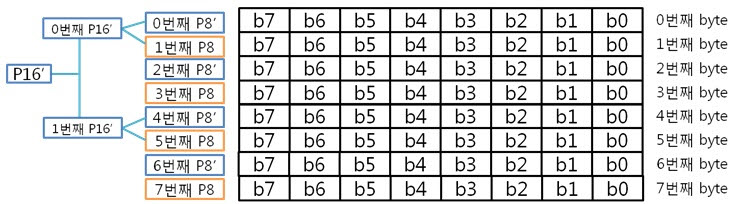
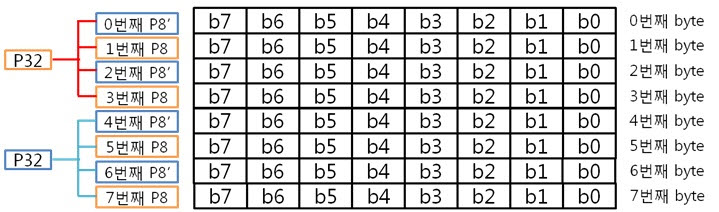
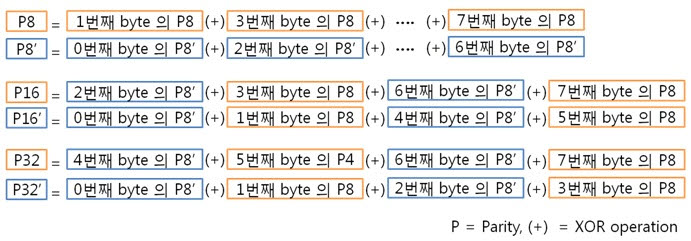
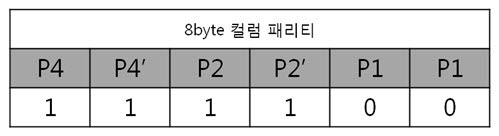
2. 8byte의 ECC 코드 만들자. 자 이제 8byte 에서 1bit 에러 찾는 것에 빠져~ 봅시다. 그 전에 4byte의 라인 패리티 쌍과 컬럼 패리티 쌍을 나타낸 것을 보시죠. 그리고 8byte의 라인 패리티 쌍과 컬럼 패리티 쌍을 나타낸 것을 보면? 어어라~? 컬럼 패리티 쌍은 추가되지 않았지만 P32, P32’라는 라인 패리티 쌍은 추가 되었습니다. 오호! 행이 증가하여도 컬럼 패리티는 증가하지 않고 라인 패리티만 증가하는군요. 이말은 결국 16, 32, 64, …, 256, 512byte 에서 1bit 에러를 찾을 때에도 라인 패리티 쌍만 증가하겠군요!. 자 다시 본론으로 돌아와서 원본 데이터 : 01 02 03 04 05 06 07 08 가 존재합니다. 우선 컬럼 패리티를 구해야 하겠죠. 어라 그런데 어떻게 구했더라? 저번시간에 봤던 1byte 컬럼 패리티 구하는 방법을 보도록 하죠. 아 맞다 맞어, 컬럼 패리티는 이렇게 구하는 것이였죠. 그런데 위에 것은 1byte인데 8byte의 컬럼 패리티는 어떻게 구해야 할까요? X의 위치를 나타내는 컬럼 패리티를 아래와 같은 방법으로 구합니다.
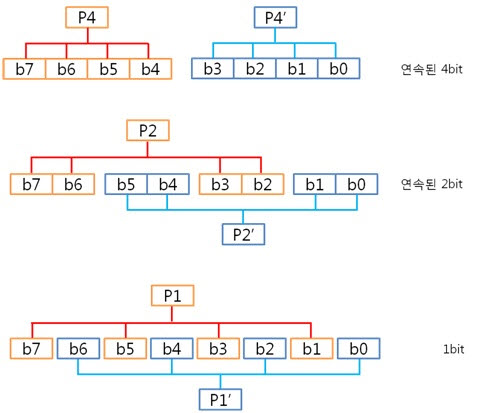
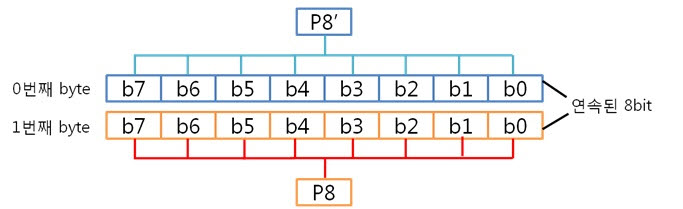
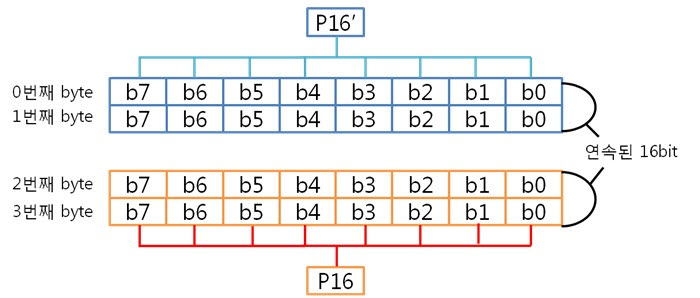
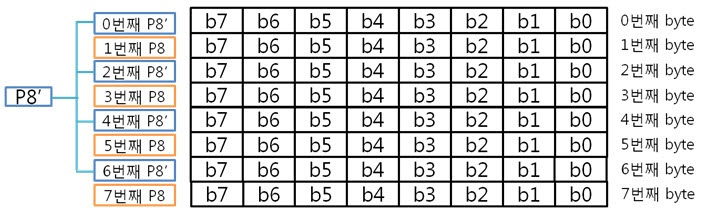
아, 그냥 각 byte의 컬럼 패리티를 XOR 연산을 하면 되는군요. 도식화 하면 스크롤이 너무 길고 이해도 힘드니 글로 하겠습니다. 각 byte의 컬럼 패리티를 구했으니 XOR 연산해서 8byte 컬럼 패리티를 구합니다. 네, 컬럼 패리티를 구했습니다. 이제는 라인 패리티를 구해야겠죠? 구하기 전에 라인 패리티 쌍을 구하는 방법을 보도록 하죠. 위에 보니 연속된 8bit까지는 할 수 있겠는데 연속된 16, 32bit를 XOR 연산할려니 참으로 귀찮지 않을까요? 그래서 이것은 요렇게 계산 할 수 있습니다.
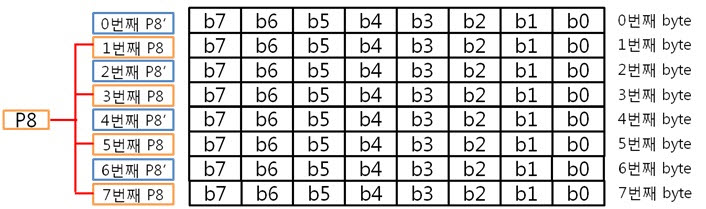
그렇죠! 각 byte의 P8, P8’을 이용하여 라인패리티를 구하는 것이 속이 편합니다. 그럼 위처럼 구해보도록 합시다.
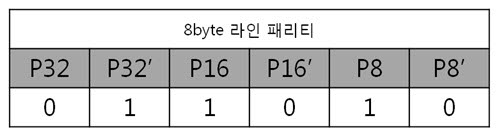
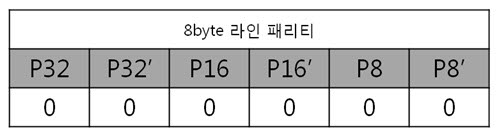
각 라인 패리티 값을 XOR 연산해서 8byte 라인 패리티를 구합니다.
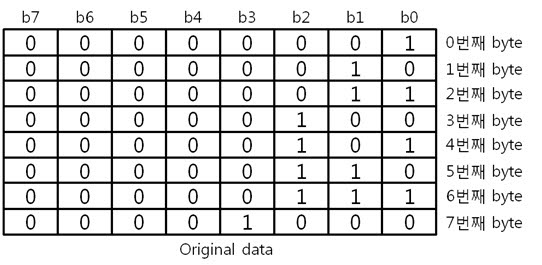
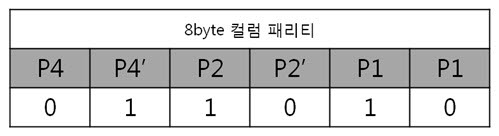
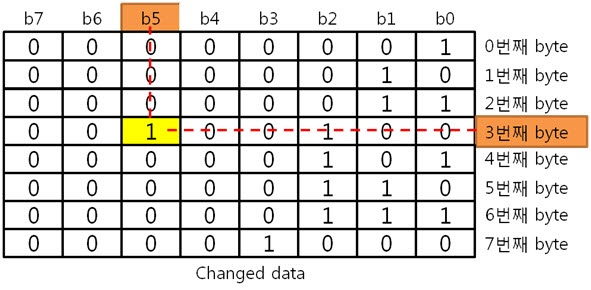
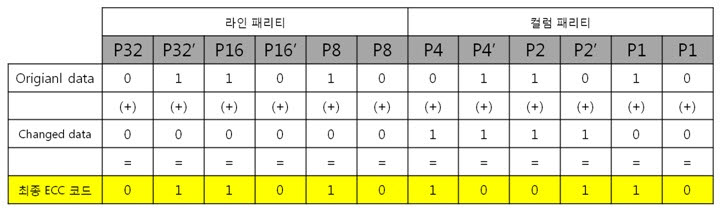
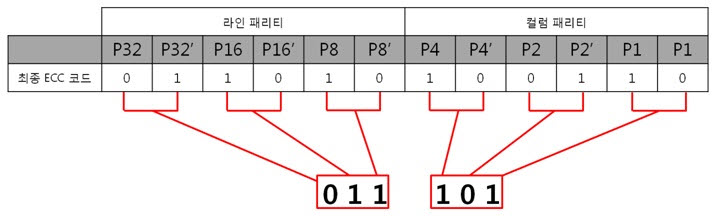
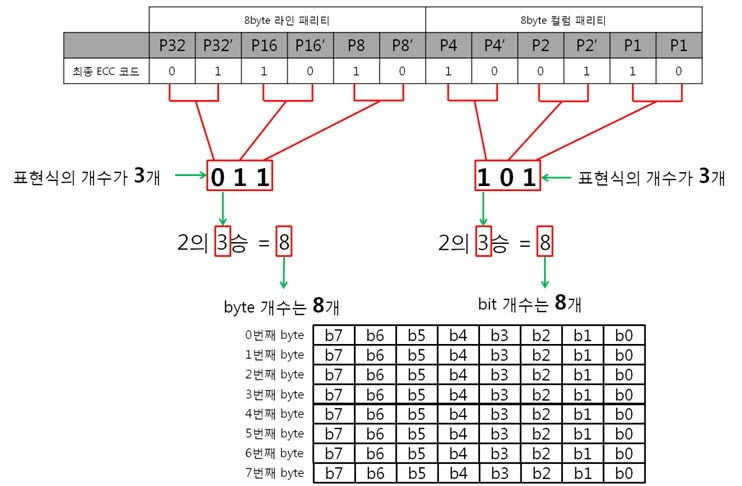
이리하여, 8byte 원본 ECC 코드를 구했습니다. 복잡할 것 같지만 전혀 복잡하지 안습니다~. 자, 오늘도 역시 원본 데이터와 원본 데이터의 ECC 코드를 NAND에 씁니다. 그런데 어떠한 외부 요인에 의해 데이터가 바뀌었습니다. 그리고 저희는 NAND에 있는 바뀐 데이터를 읽습니다. 읽어보니 아래와 같습니다. 바뀐 데이터 : 01 02 03 36 05 06 07 08 위에 보면 3번째 byte의 5번째 bit에서 에러가 발생하였습니다. 하지만 읽은 데이터가 원본인지 아닌지 모르기 때문에 읽은 데이터의 ECC 코드를 생성합니다. 방법은 같습니다. 컬럼 패리티를 구하고, 라인 패리티를 구하면 됩니다. 각 byte 컬럼 패리티를 구합니다. 각 byte의 컬럼 패리티를 구했으니 XOR 연산해서 8byte 컬럼 패리티를 구합니다. 네, 컬럼 패리티를 구했습니다. 이제는 라인 패리티를 구합니다. 각 라인 패리티 값을 XOR 연산해서 8byte 라인 패리티를 구합니다. 드디어, 바뀐 데이터의 ECC 코드를 구했습니다. 그러면 원본 데이터와 비교를 해보실까요? 드디어 8byte의 최종 ECC 코드를 구했습니다. 이 최종 ECC 코드의 패리티 쌍을 표현식으로 바꾸어 에러가 난 비트를 찾아 보죠! 짜잔! 라인 패리티는 ‘011’을, 컬럼 패리티는 ‘101’ 이라는 결과가 나왔습니다. 이것을 10진수로 바꾸어 보면 라인 패리티는 3, 컬럼 패리티는 5 라는 숫자가 나옵니다. 으헛 에러가 난 위치는 3번째 byte(행)의 5번째 bit(열) 이군! 당장 고쳐주마. 3. 의문을 풀어보자.
저번시간에 ‘1byte의 1bit 에러를 검사하고 고치기 위해 6bit나 쓰다니 이게 무슨 배꼽이 큰 경우인가요?.’라는 의문을 가졌었는데 기억하십니까? 아래의 3가지 경우를 보시면서 의문을 풀어보도록 하죠. 1byte의 경우) 2byte의 경우) 8byte의 경우) ㅇ ㅏ~ 보니까. 아무리 행이 증가하여도 X(열)의 크기는 8bit로 고정이네요. X축에서 에러를 찾으려면 컬럼 패리티 쌍을 표현식으로 바꿔야 합니다. 이때 나오는 표현식의 개수는 3개죠. 그래서 총 6개의 패리티 비트가 필요한 것입니다. 결국, 1byte에서 X축의 에러를 찾을 때 6bit를 쓰는 것은 배꼽이 큰 것이지만, 8, 16, 32, …, 256, 512byte에서 X축의 에러를 찾을 때 6bit를 쓰는 것은 배꼽이 큰게 아니라는 결론이 나옵니다!. 4. 깜짜악 퀴즈!
여기서 깜짜악 퀴즈! 그렇다면 256 byte의 ECC 코드는 몇 비트로 이루어져 있을까요? 네 쉽죠? 일단 열의 크기가 8비트니까 표현식 3비트가 필요합니다. 이 표현식은 패리티 쌍으로 이루어 진 것이기에 *2를 합니다. 그러므로 열의 에러를 찾기 위해서는 총 6비트가 필요합니다. 행의 크기는 256이니까 표현식 8비트가 필요합니다. 이 표현식은 패리티 쌍으로 이루어 졌기에 *2를 합니다. 그러므로 행의 에러를 찾기 위해서는 총 16비트가 필요하네요. 결과적으로 256byte의 ECC 코드는 6+16 = 22 비트, 총 3byte로 이루어져 있다는 것을 알 수 있습니다. NAND는 크게 Small-Block과 Lagrg-Block으로 나눌 수 있습니다. Small-Block의 Page는 512byte의 data 영역 + 16byte의 spare 영역으로, Large-Block의 Page는 2048byte의 data 영역 + 64byte의 spare 영역으로 이루어져 있습니다. 다음 시간에는 Small-Block에서 삼성 NAND Flash ECC 알고리즘을 이용하여 에러의 검출, 에러의 종류 등에 대해 알아보도록 하겠습니다.
http://ms-osek.org/ 에 많이 놀려 와주세요!
참고자료) 삼성 NAND Flash ECC Algorithm




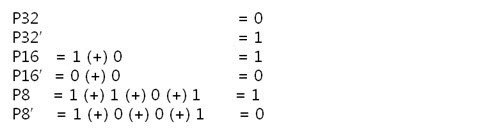




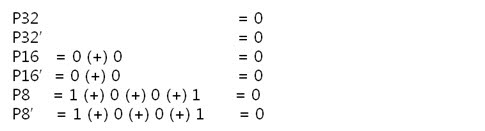

- 1. 라이트 리드.jpg (34.7KB)(1,563)
- 2. 4byte 패리티.jpg (45.0KB)(350)
- 3. 4byte 최종.jpg (27.0KB)(226)
- 4. 4byte 패리티.jpg (45.0KB)(246)
- 5. 8byte 패리티.jpg (78.4KB)(263)
- 6. 원본 데이터.jpg (37.7KB)(271)
- 7. 1byte 컬럼패리티 구하는.jpg (33.1KB)(359)
- 8. 8byte 컬럼패리티.jpg (69.7KB)(497)
- 9. 8byte 컬럼패리티 구함.jpg (137.1KB)(536)
- 10. 8byte 컬럼패리티 구함.jpg (21.7KB)(291)
- 11. 8byte 컬럼패리티.jpg (13.0KB)(195)
- 12. P8 쌍.jpg (28.1KB)(239)
- 13. P16 쌍.jpg (41.8KB)(344)
- 14. P32 쌍.jpg (71.6KB)(249)
- 15. P8 다른방식.jpg (52.4KB)(240)
- 16. P8' 다른방식.jpg (52.0KB)(248)
- 17. P16 다른방식.jpg (58.8KB)(236)
- 18. P16' 다른방식.jpg (59.0KB)(250)
- 19. P32 P32' 다른방식.jpg (55.0KB)(246)
- 20. 8byte 라인 패리티 구하는.jpg (60.5KB)(242)
- 21. 8byte 라인 패리티 구함.jpg (55.7KB)(234)
- 22. 8byte 라인 패리티 구함.jpg (9.4KB)(228)
- 23. 8byte 라인 패리티.jpg (13.8KB)(251)
- 24. 8byte 원본 ECC 코드.jpg (18.1KB)(272)
- 25. 변환된 데이터.jpg (46.5KB)(296)
- 26. 변환된 데이터 컬럼패리티 구함.jpg (132.9KB)(263)
- 27. 변환된 데이터 컬럼패리티 구함.jpg (21.5KB)(226)
- 28. 8byte 변환된 데이터의 컬럼 패리티.jpg (13.0KB)(231)
- 29. 변환된 데이터 라인패리티 구함.jpg (55.8KB)(218)
- 30. 변환된 데이터 라인패리티 구함.jpg (9.4KB)(328)
- 31. 8byte 변환된 데이터의 라인 패리티.jpg (13.3KB)(272)
- 32. 8byte 변환된 ECC 코드.jpg (18.1KB)(276)
- 33. 8byte 최종 ECC 코드 구함.jpg (39.5KB)(336)
- 34. 8byte 최종 ECC 코드 표현식.jpg (31.0KB)(346)
- 35. 1byte 표현 관계.jpg (38.7KB)(269)
- 36. 2byte 표현 관계.jpg (45.2KB)(303)
- 37. 8byte 표현 관계.jpg (69.1KB)(245)

1->4->8 진행을 보니 마방진풀이가 생각나네요^^