

강좌 & 팁
2014.03.09 17:41:26 (*.199.128.127)
104365
Java 한글Encoding
Java에서 한글이 깨지는 현상이 나타날때가 있습니다.
왜 깨질까?
이유는 간단 하더군요...Encoding이 맞지 않으니까...^^;
일단 샘플 소스를 한번 확인 해보죠..
Java 한글Encoding 샘플 소스
import java.io.UnsupportedEncodingException;
public class EnCodingTest {
public static void main(String[] args) throws UnsupportedEncodingException {
String source = "대한민국";
// java파일 기본 encoding
System.out.println("file encoding : "
+ System.getProperty("file.encoding"));
// 기본 encoding의 바이트 배열
byte[] chbyte = source.getBytes();
for (byte b : chbyte) {
System.out.printf("%02x ", b);
}
System.out.println();
System.out.println("기본 encoding 문자열 길이 : "+new String(chbyte).length());
System.out.println("기본 encoding 바이트 길이 : "+chbyte.length);
System.out.println("기본 encoding 문자열 : "+new String(chbyte));
System.out.println();
// euc-kr encoding의 바이트 배열
byte[] krbyte = source.getBytes("euc-kr");
for (byte b : krbyte) {
System.out.printf("%02x ", b);
}
System.out.println();
System.out.println("euc-kr 문자열 길이 : "+new String(krbyte).length());
System.out.println("euc-kr 바이트 길이 : "+krbyte.length);
System.out.println("euc-kr 문자열 : "+new String(krbyte));
}
}
[실행]
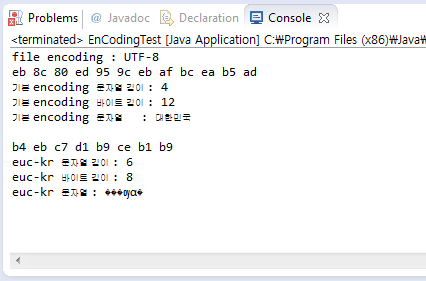
결과를 보면 Java파일의 기본 Encoding은 UTF-8입니다.
source라는 변수에 "대한민국"이라는 값을 넣으면 기본 Encoding인 UTF-8로 인식합니다.
그걸 euc-kr로 변환을 해서 찍어보면 Encoding맞지 않기 때문에 문자가 깨져서 출력됩니다.
꺼꾸로 Java파일의 기본 Encoding가 MS949(euc-kr)인 문자열을 UTF-8로 변환 한다면 똑같이
한글이 깨지겠죠!!
한글이 깨지지 않게 할려면 만들어진 Encoding로 변환을 해야만 한글이 깨지지 않습니다.
당연한 말로 들리 시겠지만...
저두 처음에 제대로 이해를 하지 못해 이게 뭔소린가 했었습니다.
나중에 Encoding에 대해 이해를 하니 그때 좀 이해가 되더라구요... ^^
UTF-8의 문자열은 UTF-8로 EUC-KR의 문자열은 EUC-KR로 변환을 해야하며...
UTF-8문자열을 아래와 같이 한다고 해서 EUC-KR로 변환 되지 않습니다.
String str = new String(byte[], "EUC-KR"); <- 이렇게 쓰면 안됨.
그래도 이해가 되질 않는다면 샘플 소스를 보면서 곰곰히 생각해보고 소스도 이것저것 변형시켜보고
깨닭음을 얻으세요...^^;
감사합니다.
